Kafka - Popular Use Cases
1. Introduction to Apache Kafka
- Kafka started as a tool for log processing at LinkedIn.
- It has evolved into a versatile distributed event streaming platform.
- Its design utilizes immutable append-only logs with configurable retention policies, making it useful beyond its original purpose.
2. Log Analysis
- Initially designed for log processing, Kafka now supports centralized, real-time log analysis.
- Modern Log Analysis:
- It involves the centralization of logs from distributed systems.
- Kafka can ingest logs from multiple sources like microservices, cloud platforms, and applications, handling high volume with low latency.
- Integration with ELK Stack:
- Kafka works well with tools like Elasticsearch, Logstash, and Kibana (ELK Stack).
- Logstash pulls logs from Kafka, processes them, and sends them to Elasticsearch, while Kibana provides real-time visualization.

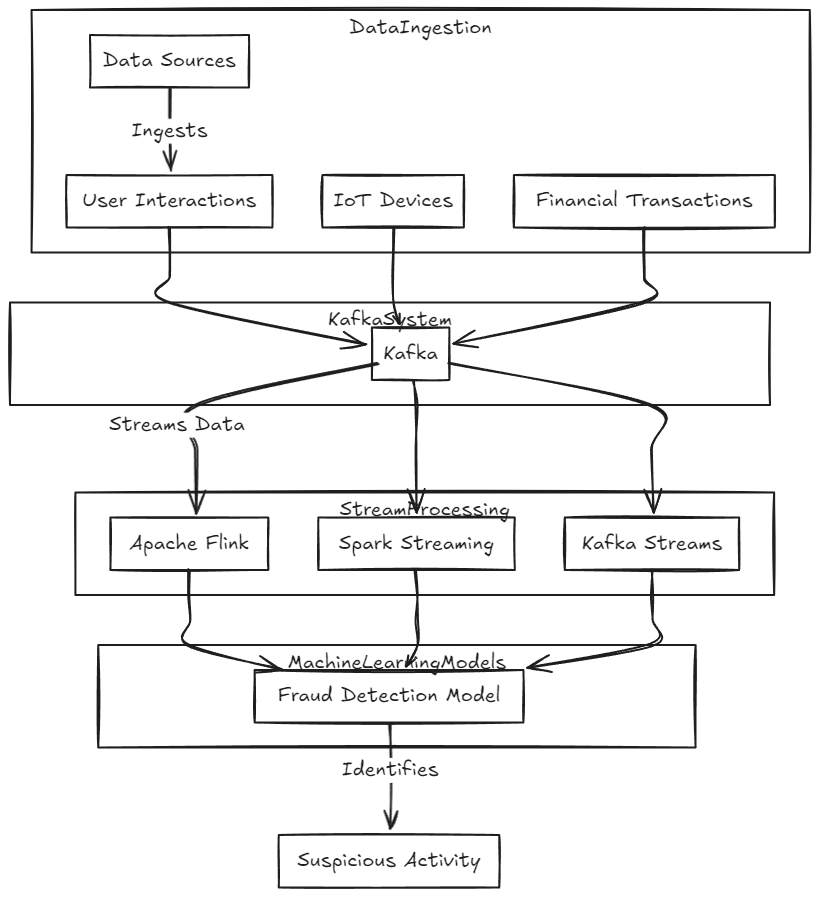
3. Real-time Machine Learning Pipelines
- Purpose: Modern ML systems need to process large data volumes quickly and continuously.
- Kafka serves as the central nervous system for ML pipelines, ingesting data from various sources (user interactions, IoT devices, financial transactions).
- Example: In fraud detection systems, Kafka streams transaction data to ML models for instant identification of suspicious activity.
- Integration with Stream Processing Frameworks:
- Works seamlessly with Apache Flink and Spark Streaming for complex computations.
- Kafka Streams, Kafka’s native processing library, allows scalable, fault-tolerant stream processing.
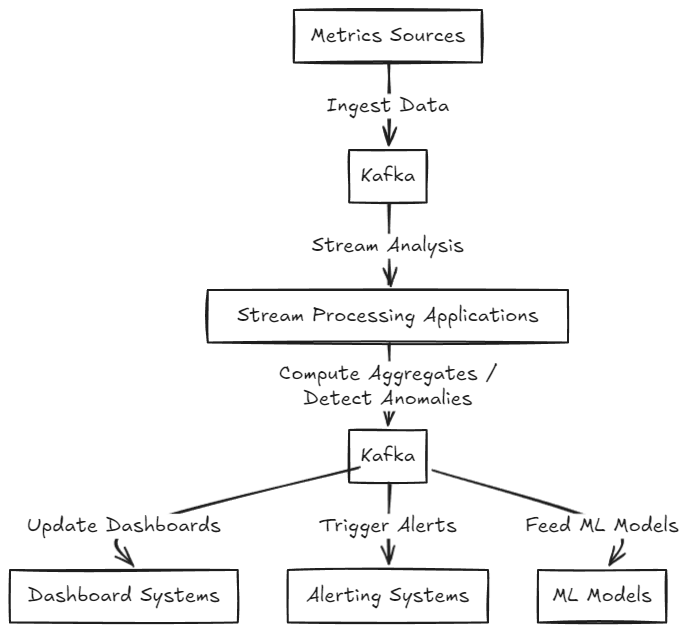
4. Real-time System Monitoring and Alerting
- Difference from Log Analysis: It’s about immediate, proactive tracking of system health and alerting.
- Kafka acts as a central hub for metrics and events across the infrastructure (application performance, server health, network traffic).
- Real-time Processing:
- Kafka enables continuous analysis and real-time aggregation, anomaly detection, and alerting.
- Kafka’s Persistence Model:
- Allows time-travel debugging by replaying metric streams for incident analysis.
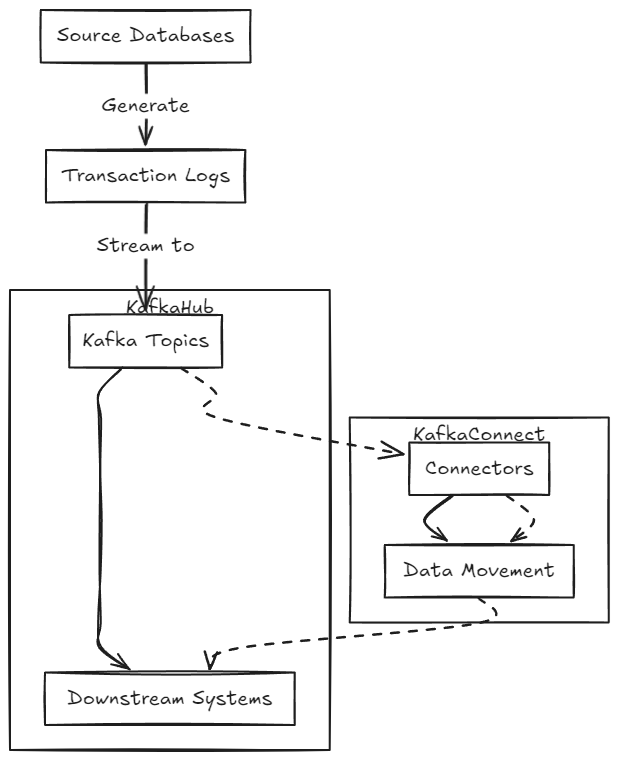
5. Change Data Capture (CDC)
- Definition: A method to track and capture changes in source databases.
- Kafka acts as a central hub for streaming database changes to downstream systems.
- Process:
- Source databases generate transaction logs that record data modifications.
- Kafka stores these change events in topics, allowing independent consumption.
- Kafka Connect:
- A framework used to build and run connectors, facilitating data movement between Kafka and other systems (e.g., Elasticsearch, databases).
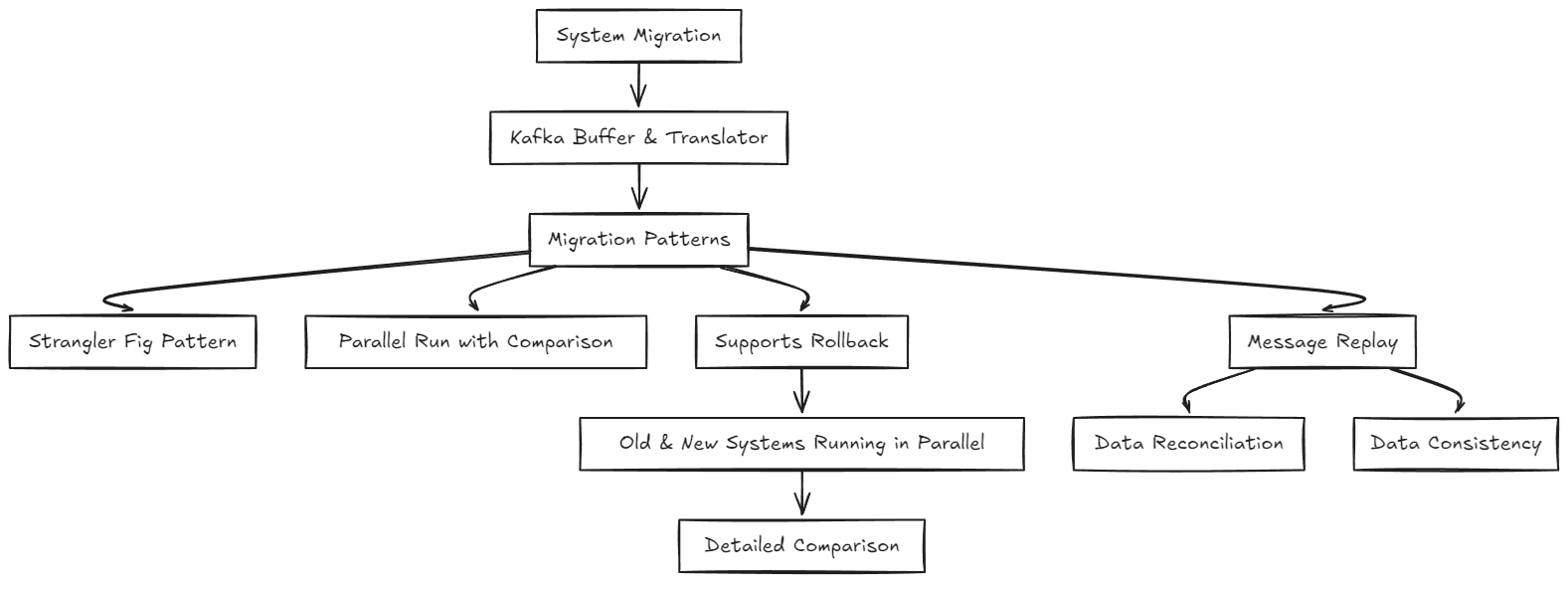
6. System Migration
- Functionality: Kafka acts as a buffer and translator between old and new systems during migrations.
- Migration Patterns:
- Supports patterns like the Strangler Fig and Parallel Run with comparison.
- Kafka allows message replay, aiding data reconciliation and consistency during migrations.
- Safety Net:
- Supports running old and new systems in parallel for easy rollback and detailed comparison.